Lab用时:9小时
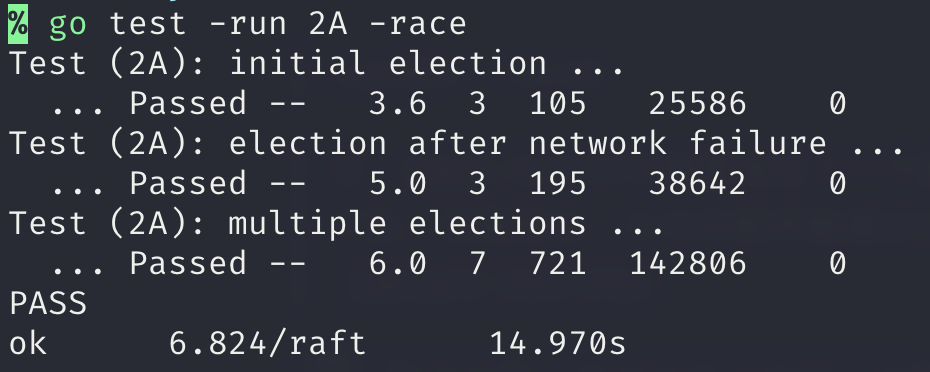
实验分析
实现Raft的Leader Election机制,保证peers能够正常选出唯一的Leader,并且在Leader故障(或网络故障)之后能够重新选举出新的Leader。
Raft paper中的Figure 2涵盖了这个Lab需要实现的所有功能,我们目前只需要关注和Leader Election有关的数据结构和要求即可。

结构设计
一些常量
const (
// Raft.state
Leader = 1
Candidate = 2
Follower = 3
// timing
MinTick = 200 * time.Millisecond
TickInterval = 300 * time.Millisecond
HeartbeatInterval = 100 * time.Millisecond
timerLoop = 20 * time.Millisecond
)
我选择的heartbeat间隔是100ms,election timeout在200到500ms之间。timerLoop是每次检查heartbeat和election是否到期的间隔,也可以按照Raft Lab的第二部分的建议改用sync.Cond。
Raft
除了已经给出的部分字段外,我这里还实现了以下的字段。
type Raft struct {
currentTerm int // 当前term号
votedFor int // votedFor = -1表明当前term还未投票时
// for leader election:
state int // leader, candidate, follower
votes int // candidate竞选过程中收到的票数
heartbeat time.Time // leader发送heartbeat的计时器,当前时间大于heartbeat时,leader就该发送新一轮的heartbeat了
election time.Time // follower/candidate的竞选计时器,当前时间大于election时,follower/candidate就该发起新一轮的竞选了
}
heartbeat和election是否到期是按照time.After()或time.Before()方法和time.Now()进行比较的。
RequestVoteArgs
type RequestVoteArgs struct {
// Your data here (2A, 2B).
Term int
// protocol: 所有的CandidateId应该大于或等于0,才能保证不和votedFor的默认值-1冲突
CandidateId int
}
RequestVoteReply
type RequestVoteReply struct {
Term int // 收到RequestVote RPC请求的peer的currentTerm号
VoteGranted bool // true表示同意投票,false表示拒绝投票
}
AppendEntriesArgs
type AppendEntriesArgs struct {
Term int // 发起heartbeat的leader的currentTerm号
}
AppendEntriesReply
type AppendEntriesReply struct {
Term int // 收到AppendEntries RPC请求的peer的currentTerm号
Success bool // 在当前lab阶段,只要Term满足要求,Success就可以返回true
}
逻辑设计
本实验的难点在于总体代码框架的设计和timing的维护,在理解Raft算法的基础上,严格遵循paper中的Figure 2,代码逻辑并不难写。但一定注意,timing的维护有好多种实现方式,但是有些方式很容易写出bug,建议参考Raft Structure Advice中的思路,用长时间运行的goroutine周期性检查timing,而不要用time.Ticker和time.Timer,后者耗费了我大量时间debug,最终也没能完美修复。下面只给出ticker()的实现框架,其余部分代码请读者自行思考。
ticker
按照实验要求,ticker()在一个goroutine中周期性运行,检查follower/candidate的选举计时器是否到期,到期之后就发起新一轮的选举。我把进行选举的方法封装在了holdElection()方法中。holdElection()方法的实现略。
// The ticker go routine starts a new election if this peer hasn't received
// heartsbeats recently.
func (rf *Raft) ticker() {
for rf.killed() == false {
rf.mu.Lock()
if rf.state == Follower || rf.state == Candidate {
if time.Now().After(rf.election) {
rf.holdElection()
}
}
rf.mu.Unlock()
time.Sleep(timerLoop)
}
}
beater
仿照给出的ticker方法,构造一个维护Raft.heartbeat的方法beater,和ticker一起在Make方法中调用。beater()方法的实现略。
踩坑
除了我上面说的用了time.Ticker和time.Timer维护timing。就是我起初在很多方法中写了很多检测是否持有锁的代码,本是想让我的代码能在我不小心写错之后能够报错提醒我,让我能够意识到一些隐性bug,于是写了很多Mutex.TryLock()之类的代码,也把锁的粒度调整的很细致。后来我发现写更多这种代码本身就在引入新bug……耗费了我大量时间debug,最后还是有些bug排查不出来QAQ,也有很多race condition处理不掉。
后来我终于妥协,遵循Raft Locking Advice中的locking protocol,人为保证执行critical section的代码要保证已经持有lock,这虽然不能完全避免自己忘掉先hold lock的情况,但可以配合go的race detector手动排错,总的来说比我上面说的那种方式要更容易写代码和debug。按照这种方式,我用很短的时间就把代码完全重构了,一遍就通过了测试。
应该在代码性能vs简洁性之间做权衡,不要太极端的偏向任何一方。
优化空间
当前阶段不需要在AppendEntries方法中处理log,我一我直接把发送AppendEntries的RPC请求的代码直接写到了beater方法中。写后续lab的时候应该要把这部分代码封装到一个方法中,根据参数选择发送带log的RPC请求或是不带log的heartbeat。
总结
收获
吸取了上次做MapReduce实验的教训,这次早早地写了个Debugf函数用来输出调试信息,按照Lab guidance的建议开启了log包的Lmicroseconds flag,然后规范了Debugf的输出格式,输出的日志要清晰地多,也只需要更改一个package-level的DebugOpen值从改为false就可以关掉日志输出,确实方便太多。
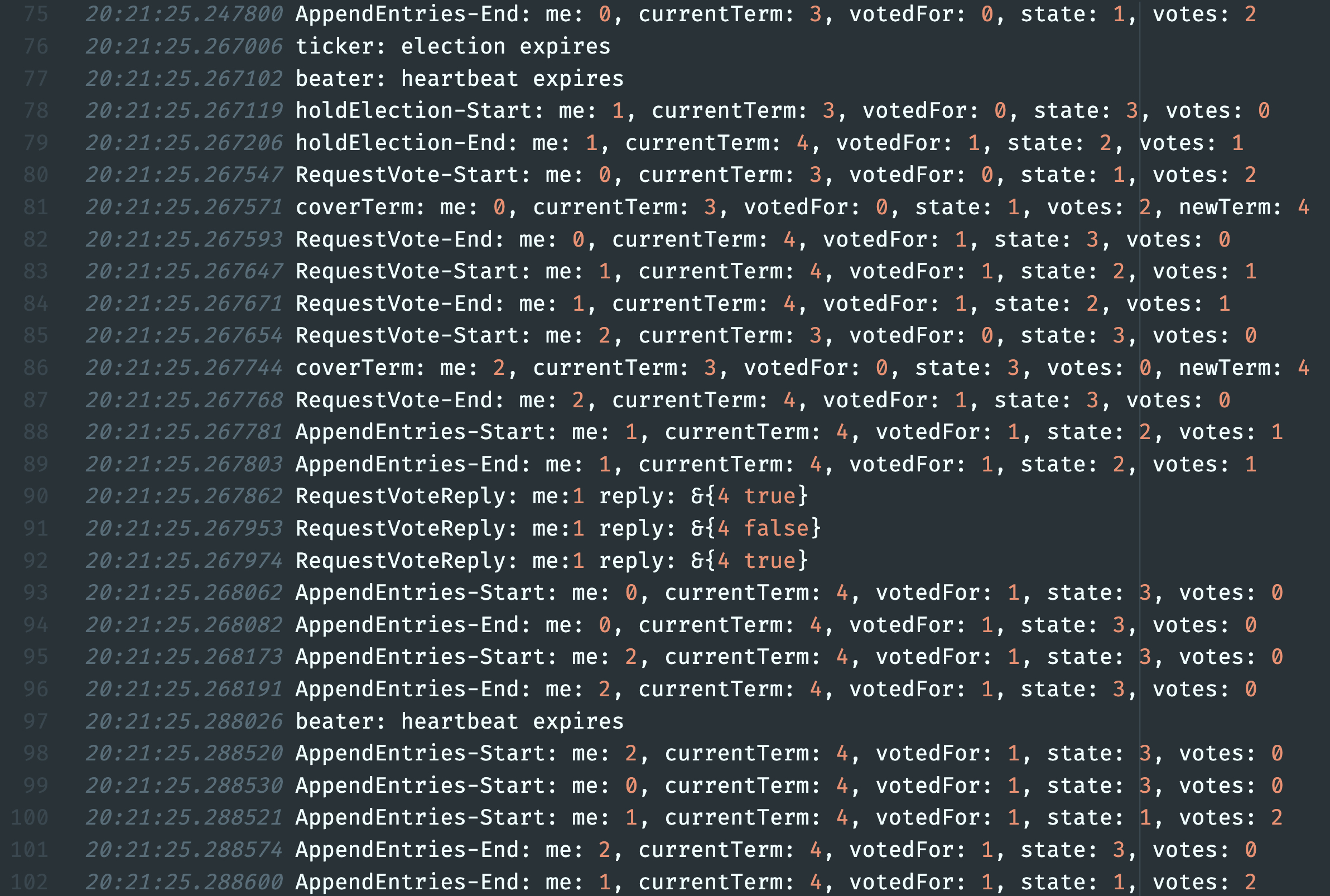
Debugf是这么写的:
const DebugOpen = true
func Debugf(format string, v ...interface{}) {
log.SetFlags(log.Lmicroseconds)
if !DebugOpen {
return
}
log.Printf(format, v...)
}
我对我这次写的Lab代码还是比较满意的,感觉我的debug能力和代码设计能力有明显提高,对后续的课程也更有信心。
教训
写这种Lab最终要的原则是千万不要在没搞懂Lab要求或者没看懂paper算法之前上手写代码,应该重复读paper直到能完全理解,再在纸上写好实现思路,最后写代码。
MIT6.824给出的Lab Guide几乎涵盖了Lab中的所有难点/易错点,已经多次预判了我代码中出现的问题,务必遵守,能节省非常多debug时间。Not doing it leads down a long, winding path of blood, sweat, tears and despair.