Lab用时:14.5小时
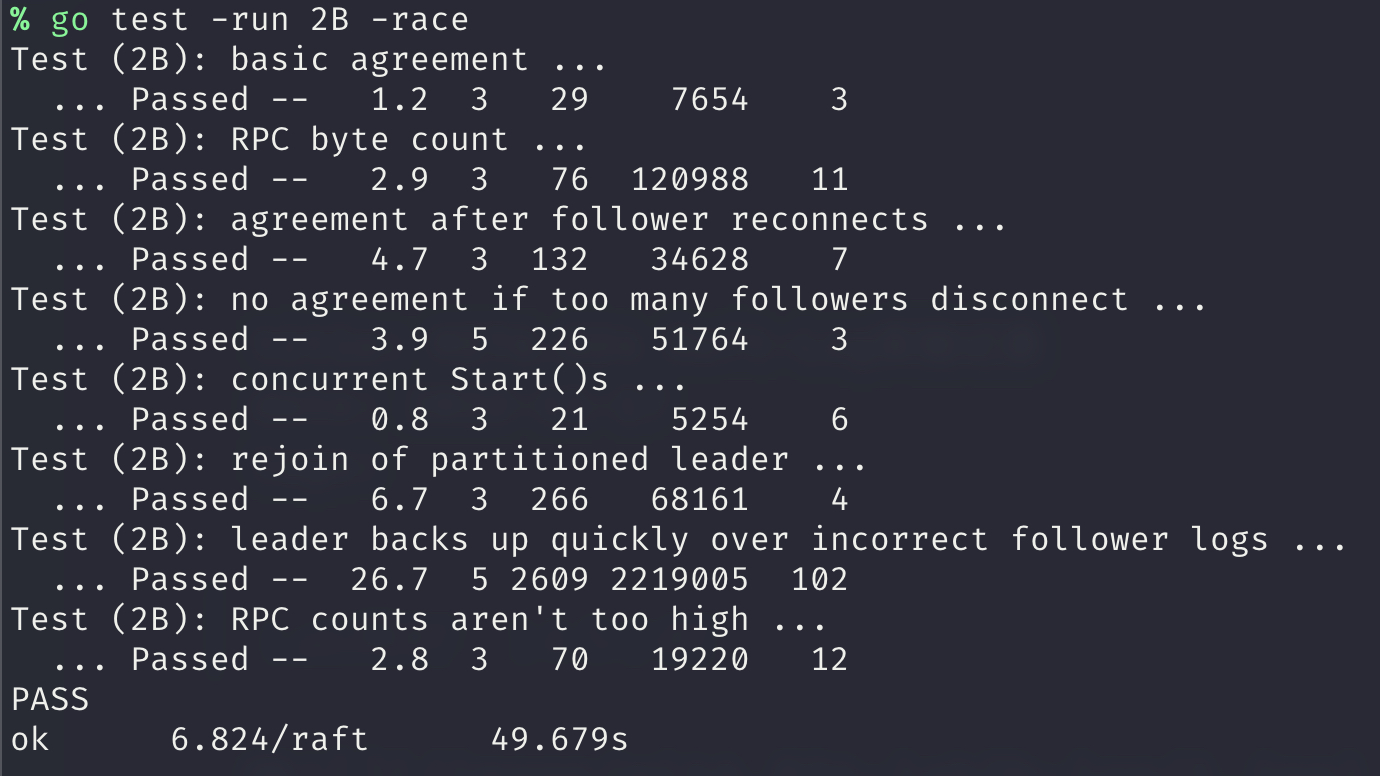
实验分析
本实验要让Raft在在上一个Leader Election的基础上,对clients的请求做出响应,接受clients的command,并在command被安全committed后响应clients。
Raft paper中的Figure 2仍然是最有价值的参照:

我们需要实现:
- leader要能够把
Start方法的command参数append到自身的log中,然后通过AppendEntries RPC把log发送给别的peers。 - followers不能仅把
AppendEntries RPC当作heartbeat,还要把RPC参数和自己的log比较,并在恰当的时机修改自身的log相关的字段,并返回Figure 2要求的reply。 - 注意上一个Leader Election lab中并没有要求实现paper中5.4.1章节的Election Restriction,我们还需要在
RequestVote RPC handler中实现。
结构设计
这里只写相较于Leader Election需要增添或更改的部分。
logEntry
除了必须的Term和Command字段外,我也把log的Index写入了logEntry中,这样代码会更加简洁,详见我后面踩坑部分的解释。
type logEntry struct {
Index int
Term int
Command interface{}
}
Raft
除了Leader Election中已经实现的字段外,对于这个lab,我加上了这些字段:
type Raft struct {
log []logEntry // 自身的log条目
commitIndex int // 最近一次commit的log的index,要保证这个字段只能单增
sequreCommit int // 可以安全commit的log的index
// paper中nextIndex字段我没有用到,实测只需要matchIndex就足够了,维护nextIndex的状态反而会使代码逻辑更加复杂
matchIndex []int // 长度为peers的数量,表明当前peer和别的peers匹配成功的最大log index
applyCh chan ApplyMsg // 每当commitIndex递增时,就应该向applyCh发送一个ApplyMsg,以供Tester测试
}
RequestVoteArgs
Leader Election只需要Term和CandidateId,若要实现5.4.1的Election Restriction,还需要加上LastLogIndex和LastLogTerm两个字段。
type RequestVoteArgs struct {
Term int
CandidateId int
LastLogIndex int // 发送RequestVote的peer的最新的log的index
LastLogTerm int // 发送RequestVote的peer的最新的log的term
}
AppendEntriesArgs
type AppendEntriesArgs struct {
Term int
LeaderId int
PrevLogIndex int // AppendEntries假定的此peer拥有的最新的log的index
PrevLogTerm int // AppendEntries假定的此peer拥有的最新的log的term
Entries []logEntry // 需要append的logEntry
LeaderCommit int // RPC发起者的secureCommit的
}
逻辑设计
这一部分的lab涉及很多log的更新,debug难度比Leader Election难很多。而且需要精心设计、分析一些机制的实现思路,否则非常容易栽到某写edge cases,然后坠入debug的深渊一去不返……如果能选定合适的实现思路,那代码逻辑并不难写,在Leader Election的代码基础上修修补补即可。
committer
效仿之前Leader Election的ticker()和beater(),我又写了一个committer(),用来递增commitIndex并向applyCh发送ApplyMsg。对于leader,还要更新secureCommit的值,这里我参考了别人的实现思路,对matchIndex排序,把中间值设定为secureCommit。也原子化绑定了commitIndex和发送ApplyMsg操作、保证了commitIndex是单增的。
func (rf *Raft) committer() {
for rf.killed() == false {
rf.mu.Lock()
if rf.state == Leader {
n := len(rf.peers)
commitNums := make([]int, n)
copy(commitNums, rf.matchIndex)
sort.Ints(commitNums)
rf.commitIndex = rf.secureCommit
rf.secureCommit = commitNums[n/2]
}
for rf.commitIndex < rf.secureCommit {
rf.commitIndex++
applyMsg := ApplyMsg{
CommandValid: true,
Command: rf.log[rf.commitIndex].Command,
CommandIndex: rf.log[rf.commitIndex].Index,
}
rf.applyCh <- applyMsg
}
rf.mu.Unlock()
time.Sleep(timerLoop)
}
}
Start
Start()方法负责把tester/clients的command添加到自身的log中,然后直接return。
func (rf *Raft) Start(command interface{}) (int, int, bool) {
// Your code here (2B).
rf.mu.Lock()
index, term, isLeader := rf.log[len(rf.log)-1].Index+1, rf.currentTerm, rf.state == Leader
if rf.state != Leader {
rf.mu.Unlock()
return index, term, isLeader
}
log := logEntry{rf.log[len(rf.log)-1].Index + 1, rf.currentTerm, command}
rf.log = append(rf.log, log)
rf.mu.Unlock()
return index, term, isLeader
}
这个时候读者可能会意识到一个问题,就是我们什么时候向peers发送包含log信息的AppendEntries RPC呢?
Students’ Guide to Raft中明确说明了,heartbeat和一般的含有log信息的AppendEntries不仅仅是都通过AppendEntries RPC来调用,同样需要完全按照AppendEntries RPC handler的流程对待。
Many of our students assumed that heartbeats were somehow “special”; that when a peer receives a heartbeat, it should treat it differently from a non-heartbeat
AppendEntriesRPC. In particular, many would simply reset their election timer when they received a heartbeat, and then return success, without performing any of the checks specified in Figure 2. This is extremely dangerous.
但我没有按照guide把heartbeat的log长度设为0,而是做的更极端了一点:直接让heartbeat也能带有logEntry。这样能在candidate成为leader之后,立即把自身的所有log发送给别的peers,然后根据响应更新matchIndex,再之后网络连接稳定的情况下,followers和leader的log能保持一致,此时的heartbeat中不包含logEntry,AppendEntries RPC handler也就不会更新自身的log了。实现的关键在于sendHeartbeat和AppendEntries。
sendHeartbeat
sendHeartbeat()根据matchIndex对所有peers(包括leader自身)发送带有合适logEntry的AppendEntries RPC请求,并在reply.Success == true时递增matchIndex。
注意这里不能直接使用matchIndex[i] += len(args.Entries),否则若出现RPC交错的情况,matchIndex的值可能会减少,就不符合matchIndex的单增性质;也不能直接用matchIndex[i] = args.PrevLogIndex+len(args.Entries),在RPC交错的时候也可能导致matchIndex的值减少(不过在lab测试中没有测试这种情况)。
注:我这里所说的RPC交错指的是:先通过RPC调用发出请求A再发出B,但是先收到B的响应再收到A的响应。但我们不能用lock序列化发送RPC并等待接受响应,这样性能损耗太大,所以只能通过类似的单增性质来保证过时的RPC响应不影响程序的正确性。
// NOTE: protocol: 必须已经hold rf.mu,再调用此方法
func (rf *Raft) sendHeartbeats() {
for i := range rf.peers {
args := &AppendEntriesArgs{
Term: rf.currentTerm,
LeaderId: rf.me,
PrevLogIndex: rf.matchIndex[i],
PrevLogTerm: rf.log[rf.matchIndex[i]].Term,
Entries: rf.log[rf.matchIndex[i]+1:],
LeaderCommit: rf.secureCommit,
}
reply := &AppendEntriesReply{}
go func(i int) {
rf.sendAppendEntries(i, args, reply)
rf.mu.Lock()
if reply.Term > rf.currentTerm {
rf.coverTerm(reply.Term)
}
if reply.Success {
rf.matchIndex[i] = max(rf.matchIndex[i], args.PrevLogIndex+len(args.Entries))
}
rf.mu.Unlock()
}(i)
}
}
AppendEntries
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
rf.mu.Lock()
defer func() {
reply.Term = rf.currentTerm
rf.mu.Unlock()
}()
// Rules for All Servers:
// NOTE: rule 1 has been implemented in committer
// 2. if args.Term > rf.currentTerm, convert to follower
if args.Term > rf.currentTerm {
rf.coverTerm(args.Term)
}
// Receiver implementation:
// 1. reply false if term < currentTerm
if args.Term < rf.currentTerm {
reply.Success = false
return
}
// 2. reply false if log doesn't contain an entry at prevLogIndex whose term
// matches prevLogTerm
lastLog := rf.log[len(rf.log)-1]
if args.PrevLogIndex > lastLog.Index || rf.log[args.PrevLogIndex].Term != args.PrevLogTerm {
reply.Success = false
return
}
// 3. If an existing entry conflicts with a new one (same index but different
// terms), delete the existing entry and all that follow it ($5.3)
var i int
for i = 0; i < len(args.Entries) && (args.PrevLogIndex+1+i) < len(rf.log); i++ {
if !checkLogEqual(rf.log[args.PrevLogIndex+1+i], args.Entries[i]) {
rf.log = rf.log[:args.PrevLogIndex+1+i]
break
}
}
// 4. Append any new entries not already in the log
rf.log = append(rf.log, args.Entries[i:]...)
// 5. If leaderCommit > commitIndex, set commitIndex = min(
// leaderCommit, index of last new entry)
rf.secureCommit = min(args.LeaderCommit, rf.log[len(rf.log)-1].Index)
reply.Success = true
rf.tickerReset()
}
AppendEntries按照Figure 2的要求来即可。
踩坑
这次lab踩坑较多:
- 一开始我的
logEntry结构中没有设定Index字段,是用数组下标来表示index的,就有很多很难处理的边界情况。后来加了Index字段之后,也在Raft启动时直接增添一个Index为0的空log,保证log的Index和数组的下标相同,这应该也能简化后面log impaction lab的代码。 - 一开始没有想到专门设一个
committer的思路,也没能把heartbeat和带logEntry的AppendEntries完全画等号,导致代码逻辑冗杂混乱。 - 虽然Students’ Guide to Raft中明确说明了
nextIndex和matchIndex是两个不同的状态,不能简单使用matchIndex + 1来表示nextIndex,但我实际发现在我的代码版本中nextIndex字段就没有存在的必要,只需要保证每个peer的matchIndex中每个位置都从0开始单增,就足以保证Raft能正常推进。不过缺点是在leader更替之后,新leader还要让matchIndex从0开始递增,会导致RPC参数体积过大,有较大网络流量。在完成log impaction lab之后应该能有效解决这个问题。 - 我本来在发送和接受RPC响应的地方写了很多检查
state状态有没有改变的代码,想借此处理RPC发送期间state改变的情况(比如:leader在发送AppendEntries请求后退位,成为follower,那就不应该处理RPC的响应了)。但paper和lab要求中没有说要实现这些,实际上也只需保证某些字段的更新限制(如单增)就能保证RPC处理的安全性。 Start方法应该尽快响应,在goroutine中处理log replication、commit的逻辑。不需要在Start中主动发起AppendEntries RPC请求,等待后台长时间运行的beater和committer处理即可。- 起初在
sendHeartbeat或者AppendEntries中写了一些检测RPC请求是否是heartbeat的代码,后来才意识到可以让这两个请求完全等价。 - 起初我用
sync.Cond计算AppendEntries RPC响应的successCnt,在successCnt超过半数时commit。后来参考别人的思路改用排序commitIndex取中值的写法,很大程度上简化了代码逻辑,在通常仅有几台的Raft集群中也几乎没有什么排序代价。 - Raft的paper字字珠玑,我一开始没有理解log是否up-to-date的含意:需要检测
args.LastLogTerm < curLastLogTerm和args.LastLogTerm == curLastLogTerm && args.LastLogIndex < curLastLogIndex两种情况。 - 在发送和接受处理RPC时,没必要对leader自身区别对待,即leader可以用尽可能少的特权,只更新维持Raft状态推进的必要状态,其余的状态通过自己对自己发送RPC来更新,能简化代码。
优化空间
还真不知道。
总结
最终的成品代码我比较满意,ticker、beater、committer这三个长时间在goroutine中运行的三个方法是非常好的一层抽象:Raft状态机在Start方法中更新自己的log状态,ticker更新state状态,beater联系别的peers更新他们的log状态,committer更新自己的commitIndex状态,相互之间有很清晰的分工和隔离,整体程序框架和代码逻辑都很清晰。
收获
有了上次Leader Election的教训,这次没有在lock上再翻车,对lock的运用要熟练很多。
这个lab不仅要处理本地程序的代码并发,还要处理网络中RPC请求、响应的并发。而对RPC加lock绝对是得不偿失的,于是通过对属性的更新设限制来保证RPC并发的安全性。这确实是我以前从未见过的处理方式,涨见识了。
教训
感觉这次写代码还是有点操之过急了,debug了非常久,下个lab可以尝试把整个完整方案从头到尾写完整,再分析每一个步骤可能带来的问题,仔细分析多个替代方案之后再开始写代码。
这好几次写lab都是写好代码后跑不过测试,然后就是一遍又一遍对着几千条日志debug,找出一个又一个问题,增改几行代码……最后终于是通过了测试,但是代码已经成屎山了,搞的自己也看不太懂。到优化代码的时候,很快就发现原来是自己的方案想错了:用的这个方案会带来很多边界情况,而这些边界情况难处理、难debug,导致了多个测试都过不去;而若是一开始就选用好的方案,压根就不会出现这么多恶心的边界情况,也就很容易debug了。以后要提醒自己写代码不能只往后写,还要时不时向前看,及时重构方案,防患于未然。
一次,魏文王问扁鹊说:“你们家兄弟三人,都精于医术,到底哪一位最好呢?”扁鹊答:“长兄最好,中兄次之,我最差。”文王又问:“那么为什么你最出名呢?”扁鹊答:“长兄治病,是治病于病情发作之前,由于一般人不知道他事先能铲除病因,所以他的名气无法传出去;中兄治病,是治病于病情初起时,一般人以为他只能治轻微的小病,所以他的名气只及本乡里;而我是治病于病情严重之时,一般人都看到我在经脉上穿针管放血,在皮肤上敷药等大手术,所以以为我的医术高明,名气因此响遍全国。”