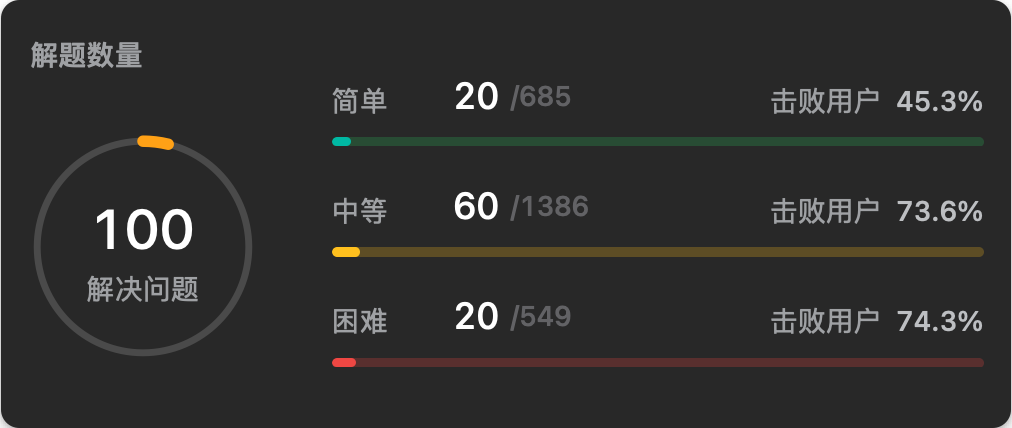
年初的时候我定下了今年刷够 300 道 LeetCode 算法题的目标,到 4 月 21 日,我已经刷够了100道题,按照每 4 个月 100 道题来算,今年的目标应该是能够达成的。
学而不思则罔,利用 4 月底的这几天时间,我对我的刷题心得做一个简单的总结。
算法题,其实也就这么回事
年初我刚开始写 LeetCode 的时候,真是连个简单题都没有思路,写不出来。我一度感觉十分沮丧,感觉自己智商受到打击了,但这其实是再正常不过的情况了,写代码本身就是需要很长时间学习思考、经历很久的练习之后才能做好的事情。
LeetCode 的评论区很有趣,大伙都喜欢在这里自黑:

大伙也很幽默:

所以说大家刚开始写算法题的时候都是差不多的情况。好在这个过程持续不了太久,大概做到二三十题的时候,基本上绝大多数的题型都遇到一遍了,这个时候再遇到见过的题型的时候就逐渐能自己解出来题了。
说到底,常见的算法题的解法大概只有以下这么几类:
- 哈希表
- 递归、回溯
- 滑动窗口
- 双指针
- 动态规划
- 二分查找
- 栈
少见的有如下几类:
- 自动机
- 数学
- 位运算
- 贪心
- 分治
涉及到的常见数据结构:
- 哈希表
- 栈
- 字符串
- 链表
- 树
所以说,算法的框架其实并不大,其中重要且常见的内容并不算多,但是需要长久的练习和总结。一种题目做得多了,再看到同类型的,下意识就能想到合适的做法了,比如说:
- 看到题目中要求
O(log n)的时间复杂度,那这道题目大概率和二分查找有关系 - 题目要求判断一个括号数组或字符串能否正确闭合,那这道题目很有可能要用
栈来做 - 根据题目中给出的参数的变化,如果内部要执行不同层级的循环,那这道题目很有可能要用
递归或回溯来做 - ……
这让我想起来了我打游戏的一些体会,职业选手们玩游戏的时候,总能一瞬间判断清楚局势、开始决策、再做出反应,在外人看来就有种**“操作看起来很流畅”或“掌控局势走向”的感觉,而自己打游戏的时候在同样的时间内只能注意到比较少的信息**,这些职业选手们能够发觉到任何一丁点的细节和机会,哪怕只有一个眼位,也能够影响到整个战局。算法能力也会给我们带来编程的这种**“敏感性”**,让我们在想要实现一个功能的时候,下意识能想到最简洁、优美的写法。
事实证明,刷算法题确实提高了我的代码水平。我原来写了一个 Python 程序,能够按照我的输入给我随机生成一个数组,方便我用作 LeetCode 题目的测试用例:
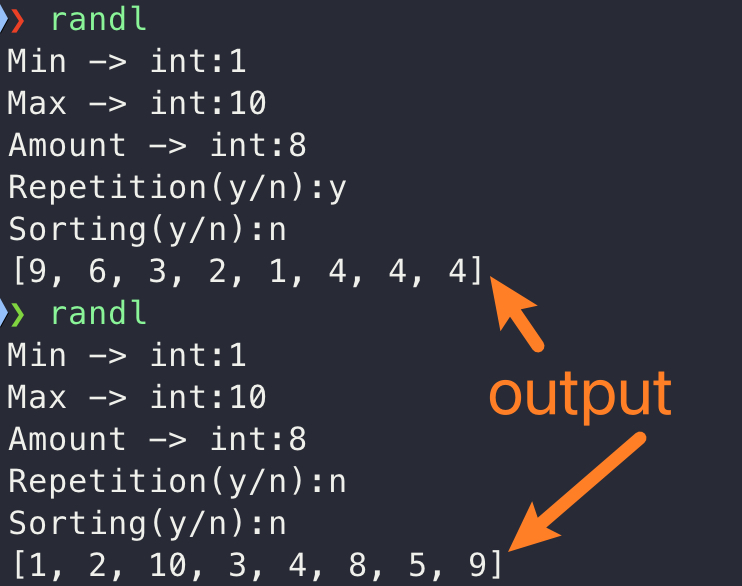
注意,这里有个 Repetition 选项,控制着生成的数组中能否出现重复的元素。这就涉及到列表元素去重的问题,起初我是将列表转化为集合,然后再转化成列表,然后再判断列表的长度是否等于输入的 amount 值,大致是这个样子:
while len(l) != amount:
l.append(random.randint(min, max))
if repetition is True:
l = list(set(l))
现在看来,这个写法简直太蠢了,于是我把它优化成了这个样子:
opt = [i for i in range(min, max + 1)]
for _ in range(amount):
i = random.randint(0, len(opt) - 1)
l.append(opt[i] if repetition else opt.pop(i))
现在这段代码运行的效率就会高很多,也不容易引发 bug,所以说,懂点算法绝对是非常必要的,都赶快刷起来吧
算法题,更多还要看思考和积累
就拿我我目前水平来说,大多数情况下半个小时能够用合适的做法做出一道 LeetCode 上 中等 难度的题目,还有非常大的提升空间,而且我写的代码质量还很差,经常写出又臭又长还容易出 bug 的代码。比如下面两段代码,都能够实现把列表中每一项数字进位到上一位,但是下面的代码就比上面的代码更简洁、优美:
# bad:
for i in range(len(digits) - 1, 0, -1):
if digits[i] == 10:
digits[i-1] += 1
digits[i] = 0
else:
break
# good:
i = len(digits) - 1
while i > 0 and digits[i] == 10:
digits[i-1] += 1
digits[i] = 0
i -= 1
这种优化就需要平时多加留意、积累、思考、观察别人代码,慢慢就会有提高,写出自己的风格,我不久前发现二分查找的写法其实有很多种,每次遇到二分查找的题目都要想一想自己写的这种写法边界条件写的对不对、最终返回的索引是不是对应的值……这样每次遇到同类题都要重新思考,就不如事先把自己的写法固定了好,所以我在网上查阅了一些资料,最终选择把自己的二分查找写法固定成下面这种:
# this version of binarySearch insure that
# "left" will be equal to "right" after finishing the while-loop
# edge case: [left, right)
while left < right:
# "mid = (left + right) // 2" might cause overflow fault in some languages
mid = left + (right - left) // 2
if arr[mid] < target:
left = mid + 1
else:
right = mid
既不会整数溢出,也能保证循环结束时 left 和 right 的值是相同的。这样再写二分查找的时候,按照这种格式直接写出来,既省心又省时。遇到这种小问题,一定得多思考,时间久了有了**“敏感性”**,代码水平也就提上去了。
写代码,慢就是快
一开始我写算法题的时候总是喜欢直接写代码,有了一个思路,不管好坏,先开写再说。这就常常会写了一半才发现“这个思路好像是错的”、“这个思路貌似不太方便写代码实现”或者“这个写法有点不够通用,应该还得加一些临界的判断条件”的情况,写完代码后也经常会发现自己写的代码也常常出 bug,不能通过所有的测试用例。
后来,我就拿一张纸、一根笔,老老实实把思路给写下来,找到一个思路后再想想有没有更好的思路,再写几组有代表性的测试用例,也搞一搞测试驱动开发。如果跑代码的时候有测试用例没有通过,也不用借助调试工具,只需把没有通过的案例写到纸上,按照自己写的代码一行一行模拟执行,最多再写几个 print 语句,用这种比较原始的方式改代码。
这又让我想起了一个艺术般的游戏——《空洞骑士》(我的一位友人写了一篇有关这个游戏的文章)。在《空洞骑士》中,玩家在游戏中期能够选择非常多的路线去收集物品,但如果像无头苍蝇一样走到哪算哪,就会耗费非常多的时间。而提早规划好路线能够让游戏难度曲线变得更加平滑、进度推进地更加顺畅。合理的路线规划能够用一个存档完成多个成就:
写代码也是一样的道理,按照我自己的经验,先在纸上写好思路再写代码实际上会节省更多时间、代码质量更高、bug 更少。大多数有经验的开发者也会先思考、讨论、设计,准备妥善之后再写代码。所以说,写代码,慢就是快。
结尾
编程是一门艺术,需要长久的练习和思考才能写出诗一般的代码,算法又是代码的核心,一位合格开发者必然要拥有合格的算法能力。很高兴我的刷题计划能够顺利进行,在变得更强的路上,我会继续努力